15時57分24秒 [ソフトウェア]
PDFをWord形式のファイルに変換したいがどうすれば良いかという質問を時々受けます。
Word文書をPDF化するのではなくて(それは昔から簡単ですね)、PDFとして受け取った書類を編集するためにWordファイルに変換したいという相談です。
この種の相談を時々受けるのであまり知られていないのだと思いますが、Microsoft Word 2013以降ならPDF形式のファイルも直接読み込めるので、そもそも変換など不要なのです。
PDFをWordで編集するためにdocx形式のファイルに変換したいなら、Microsoft WordでそのままPDFを読み込めば良いだけです。
とはいえ、PDFをダブルクリックしても(たいていの環境では)Adobe Acrobat ReaderのようなPDFビューアが開くだけですから、Wordでは開けません。なので、PDFファイルをMicrosoft Wordで開く方法などを以下に解説しておきます。
なお、お使いのMicrosoft WordがVer.2013より古い場合にはPDFを直接読むことはできません。また、PDFをMicrosoft Wordで読み込んでも、全体が画像として読み込まれてしまって編集ができない場合もあります。そのときの対策などもついでに記しておきます。
目次:
以下の方法でPDFをMicrosoft Wordに読み込ませることができます。
1は簡単なので説明の必要はないでしょう。
とはいえ、デスクトップにMicrosoft Wordのアイコンがない場合は1の方法は使えません。(頻繁にPDFをWordで読みたい場合があるなら、デスクトップにアイコンを出しておくと楽で良いと思いますが。)
その際は、2の方法が楽です。
ただ、「プログラムから開く」のリストにMicrosoft Wordがないなら、3の方法を使う必要があります。
以下に、2と3の方法について画面イメージ付きで説明しておきます。
PDFファイルを右クリックすると、下図のようにコンテキストメニューが出てきます。メニュー項目はお使いの環境によって微妙に異なりますから下図の通りではないと思いますが、メニュー内をよく見ると「プログラムから開く」という項目があるはずです。
その「プログラムから開く」をポイントしてから「Word」をクリックすると、そのPDFファイルをMicrosoft Wordで読み込むことができます。
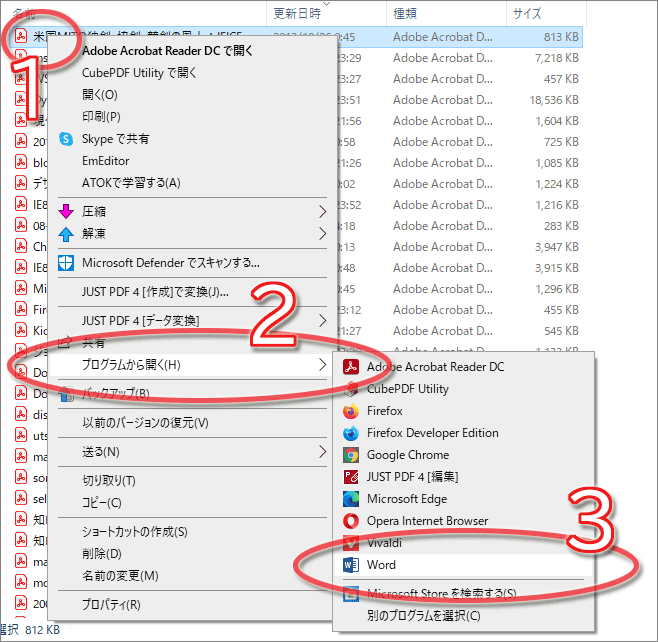
操作はこれだけです。簡単です。
(もしリストに「Word」がない場合は「別のプログラムを選択」項目をクリックしてから探すとWordが見つかるかもしれません。)
お使いのMicrosoft Wordのバージョンが2013以降なら、下図のようにMicrosoft Wordのメニューを「ファイル」→「開く」とたどってから目的のPDFファイルを選択する方法でも、PDFを直接読み込めます。
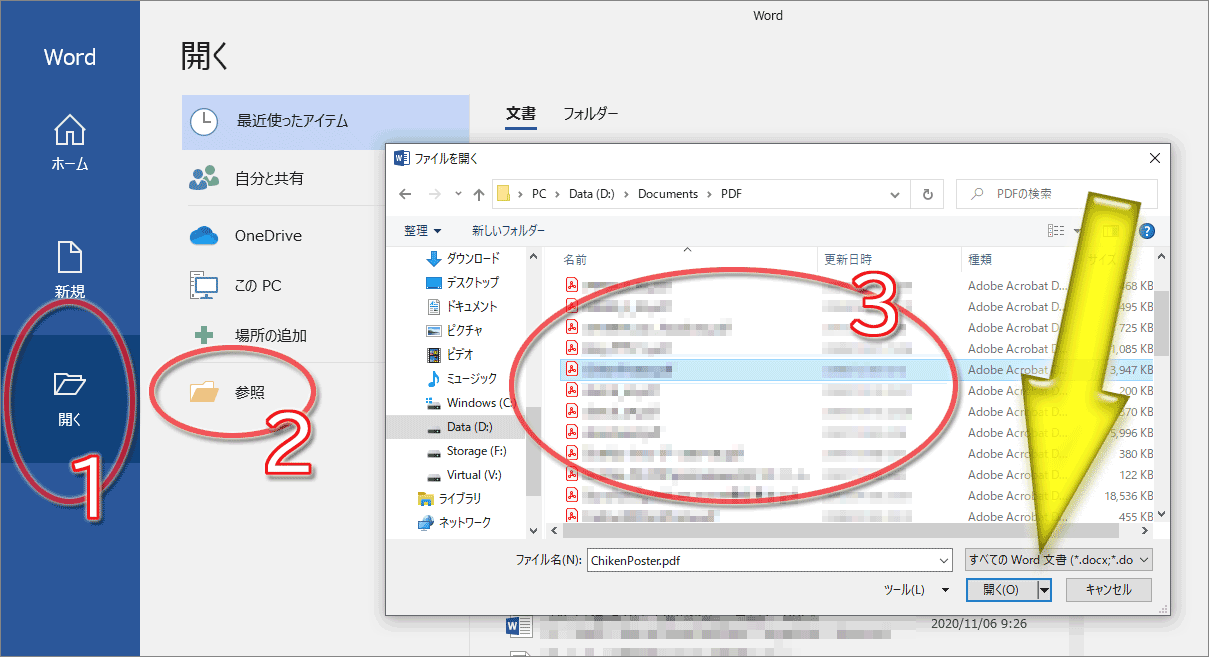
※このファイルを開く画面で拡張子.pdfのファイルが出てこない場合は、ファイル形式の選択肢(上図の黄色矢印の先)を「すべてのファイル」に変更してみて下さい。
上記の操作でPDFを開くと、以下のような注意が表示された後にWord側がPDFをWord形式に変換してから読み込んでくれます。

その後、「名前を付けて保存」メニューを使ってWord形式(.docx形式や.doc形式)で保存すれば、Wordファイルになります。
※この方法でWord形式に変換した際に、単に「大きな画像が張り付いているだけ」のWordファイルになるケースがある話は後述。
見積書のような表を含むPDFをExcelファイルに変換したいという需要もよくあります。が、残念ながらExcelではWordのようにPDFファイルを直接読むことはできません。
しかし、以下のように操作すると簡単です。
上記のように操作すると、上手い具合に表構成を維持したままExcelシートに貼り付けられるので便利です。
あとは、適当な名称で保存すれば、.xslxファイルになります。
外部の変換サービスを駆使しなくても、実は簡単です。
人力でWordからExcelにコピー&ペーストする手間は発生してしまいますけども。
PDFをExcelファイルに直接変換するWebサービスもありますが、私がちょっと試したところでは表の中身がバラバラのシートに分解される問題などがあって、あまり使い勝手が良いとは言いがたいように思いました。
変換結果を自力で整形し直す手間を考えれば、一旦Microsoft WordでPDFを読み込んでから、Wordの内部機能でPDFを変換させた結果をコピーしてExcelにペーストする方が、よほど簡単なように感じます。
例えば、以下のようなPDFだと、Wordで読み込んでも全体が画像として取り込まれるだけになります。
このような場合は、OCR(Optical Character Reader)と呼ばれる文字認識機能を使って、「画像に描かれている文字」を文字として認識して変換させる方法を使う方法があります。
OCRを利用するには、例えば、以下のような方法があるでしょう。
OCRソフトはいろいろありますから、機能を比較して選べば良いと思います。
例えば「読取革命」というソフトウェアなら、PDFを読み取ってWordやExcelファイルに変換する機能があります。
昔はPanasonic製品だったのですけども、今はソースネクストが販売しているようですね。
費用は掛かりますが、件数が多いならこのようにOCRソフトを購入して使うのが楽でしょう。
もうちょっと安い製品では、例えば「JUST PDF4 データ変換」というツールもあります。これは別途ブログ記事(任意の画像ファイルからOCRでテキスト化もできる「JUST PDF4 データ変換」)で紹介しましたが、PDFや画像を読み込んでWord等のファイルに変換する機能があります。全自動で処理すると、元のPDFによっては文字部分もそのまま画像として取り込まれてしまうケースがあるのですが、文字認識範囲を手動で調整する機能がありますので(先の記事内で画面イメージ付きで紹介しています)、その機能を使って微調整しつつ変換すれば、OCRでテキスト化ができるでしょう。認識結果の文字の修正もその場でできるので、使い慣れれば便利な気はします。
Web上で、PDFファイルをアップロードするとdocx形式のファイルに変換してダウンロードできるWebサービスがいろいろあります。「PDF Word 変換」などの検索語でググるといろいろヒットします。(特にお勧めするサービスがあるわけではないので、個別にリンクはしません。)
その手のサービスは、「基本は無料でOCR機能付きだと有料」みたいな感じで運営されているところが多そうな気がします。なので、その有料サービスを利用すればOCR機能を使って変換できるでしょう。
たいていは最初に無料のお試し期間があるでしょうから、試してみると良いかもしれません。
インストール作業等が不要で、ブラウザだけで利用できるので楽と言えば楽でしょうね。
ただ、そのPDFが機密の含まれるデータなら、他社のWebにアップロードして使うのは(安全のためには)避けた方が良いと思いますが。
いずれにしても「OCRによる文字認識」は100%の精度にはあまりなりません。取りこぼしや誤認識は必ずあると思った方が良いでしょう。
英数字だけで構成されていて標準的なフォントだけが使われている場合には99%以上の精度はあるのではないかと思いますけども、文字のすぐ傍に罫線が含まれていたり、特殊な記号が含まれていたり、珍しいフォントで書かれていたりすると、誤認識の可能性が高まります。
なので、必ずしも使い物になるデータに変換できるとは限りませんから注意して下さい。
(とはいえ、1から人力でテキスト化するよりは遙かに楽なことは間違いないと思いますが。)
というわけで、PDFをWordに変換する方法の話でした。
この日記へのコメントはお気軽に! コメント数:0件
コメント数: 0件