15時09分08秒 [ソフトウェア]
ジャストシステム製のWindows用PDF編集ツールの1つに「JUST PDF4 データ変換」というソフトウェアがあるのですけども、名称にある「PDF」とは関係なく、任意の画像ファイルからでもOCRでテキストデータ化する機能があることに気付いて驚きました。
「JUST PDF4」という名称が少々損をしているのではないでしょうかね。なんとなくPDFしか対象にできないのかと思ってしまう名称だと思うのですけども。
単品でも販売されているソフトですが、ジャストシステム製のワープロソフト「一太郎」(プラチナ版)のおまけとしても付いてきます。
過去にタブレットでキャプチャしていた電子書籍の1ページを取り込んでみて、何気なくテキスト化を試してみたところ、「どうせ『扱えません』的なエラーが出るのだろうな」と予想していたのですが、すんなりOCRでテキスト化ができて驚きました。
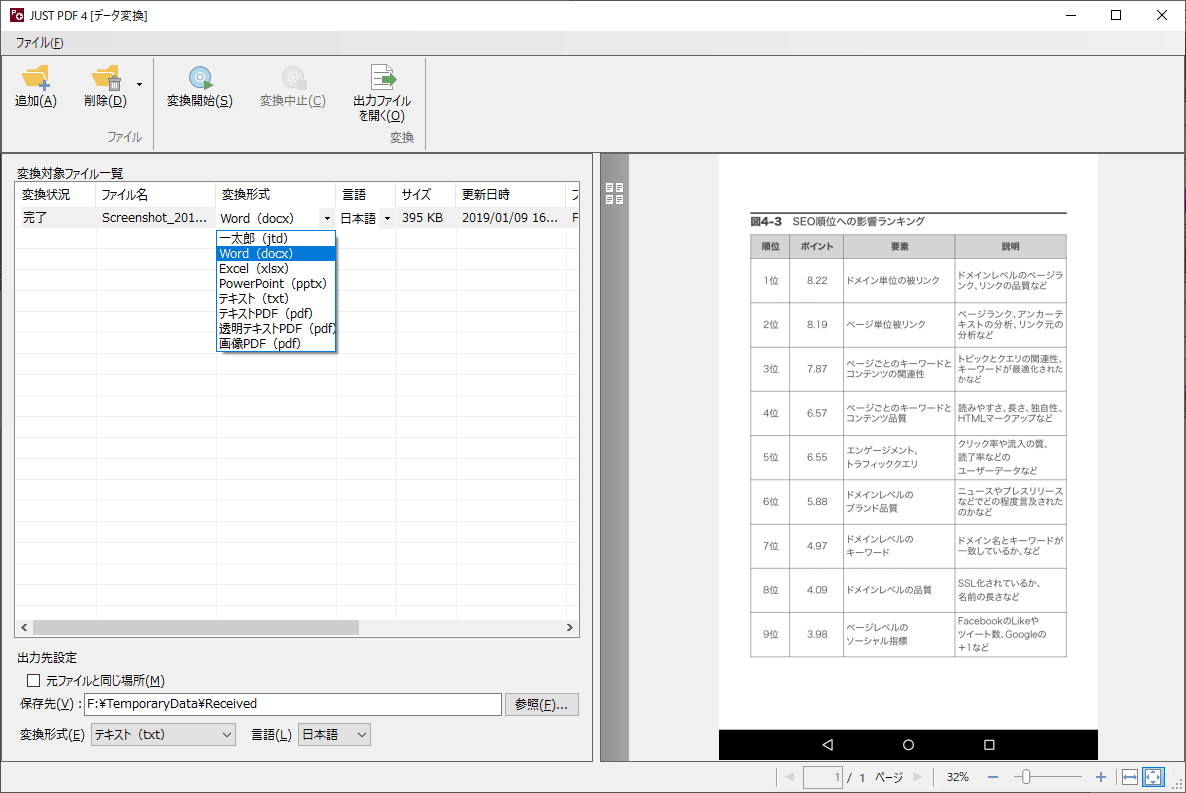
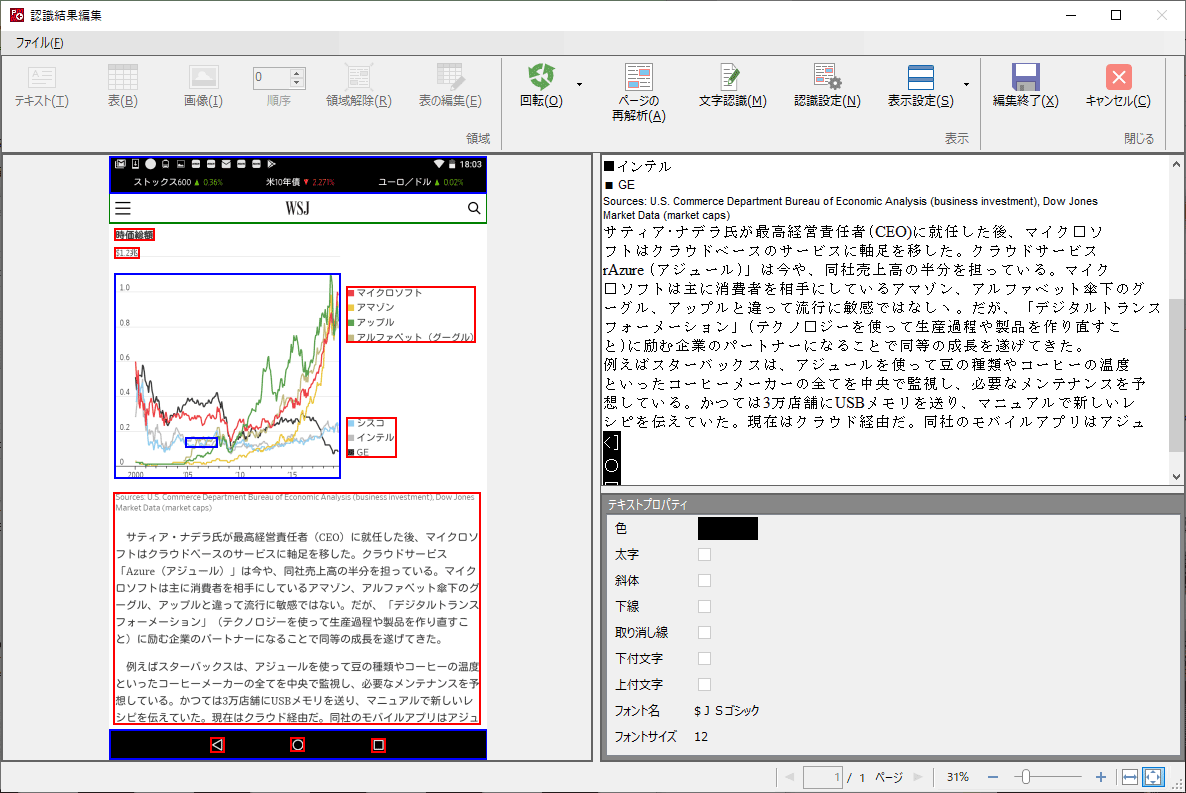
上図はAndroid端末上で電子書籍の罫線(表組み)ページをキャプチャした画像を「JUST PDF4 データ変換」に取り込んだところです。
これをMicrosoft Wordの.docx形式と一太郎の.jtd形式にそれぞれ変換してみたのが下図です。
表組も問題なく罫線で表現されていますし、テキストデータ化された日本語もほぼ正しいです。1点だけ読点が「x」になっていますけども、OCRではこの程度は仕方ないでしょう。
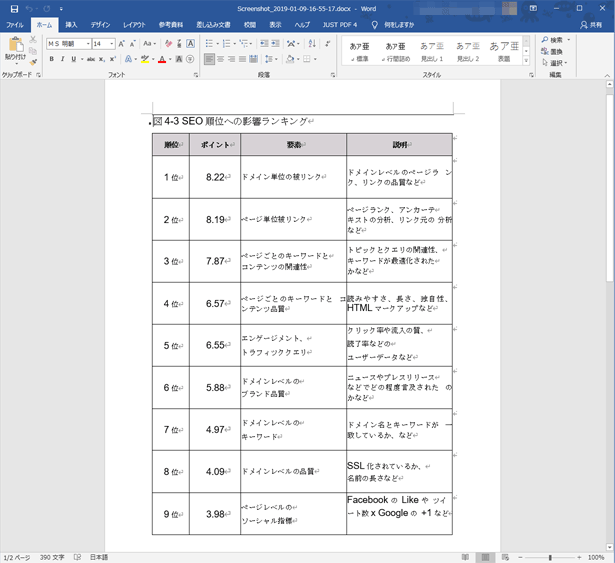
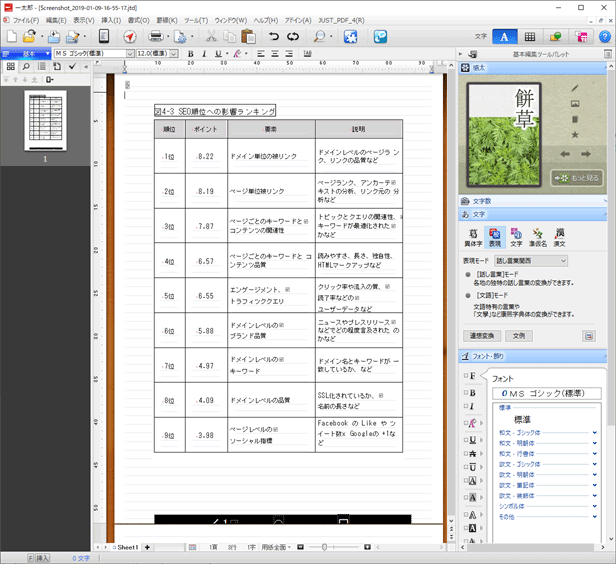
私は昨年に購入した「一太郎2020 プラチナ版」に含まれているオマケ機能として手に入れたのですけども、まさかこんなに有用なオマケだったとは今まで気付きませんでした。
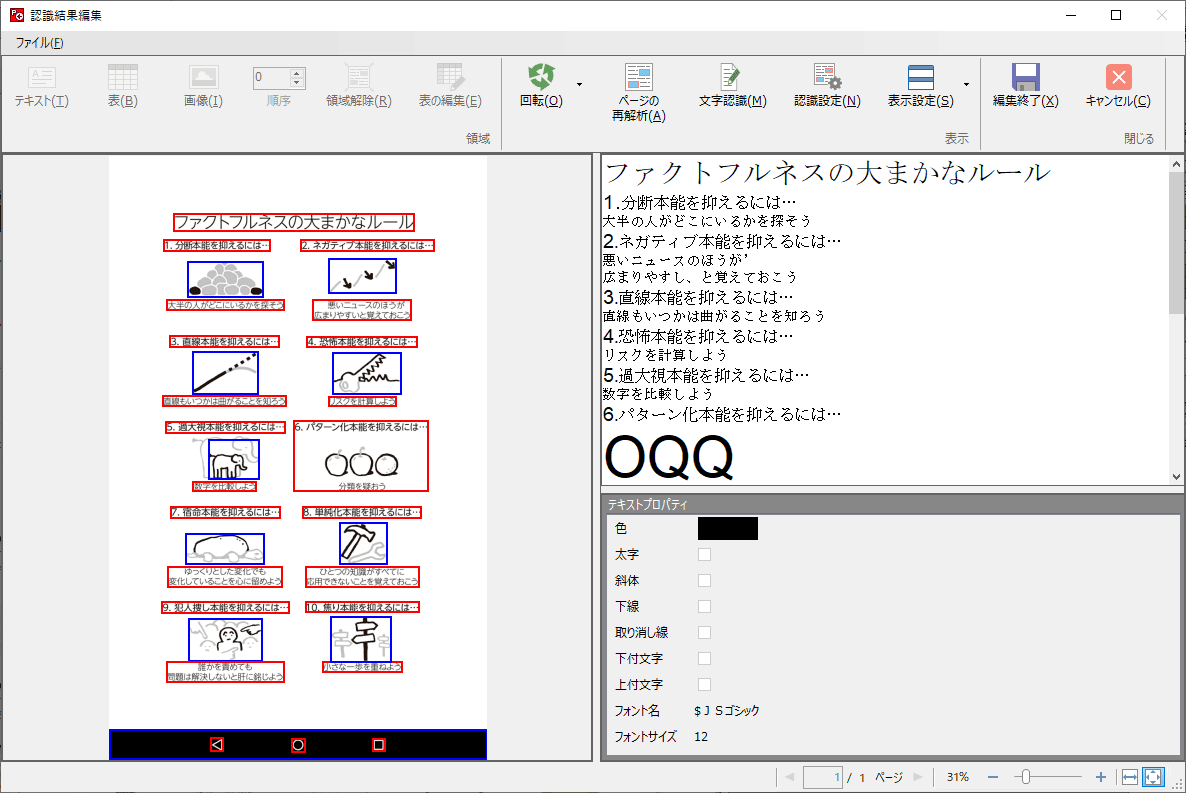
どの部分をOCRで文字として認識しているのかを表示するモードもありました。
認識はほぼ正しい(リンゴやミカンの絵が「OQQ」と認識されている程度)のですが、必要に応じて認識範囲を手動で修正することもできるようです。
認識結果のテキストを直接編集することもできるので、ここで事前に編集しておけば編集結果を最終データとして出力できるっぽいです。なかなか便利です。無駄な改行もここで取り除いておけば楽かもしれません。
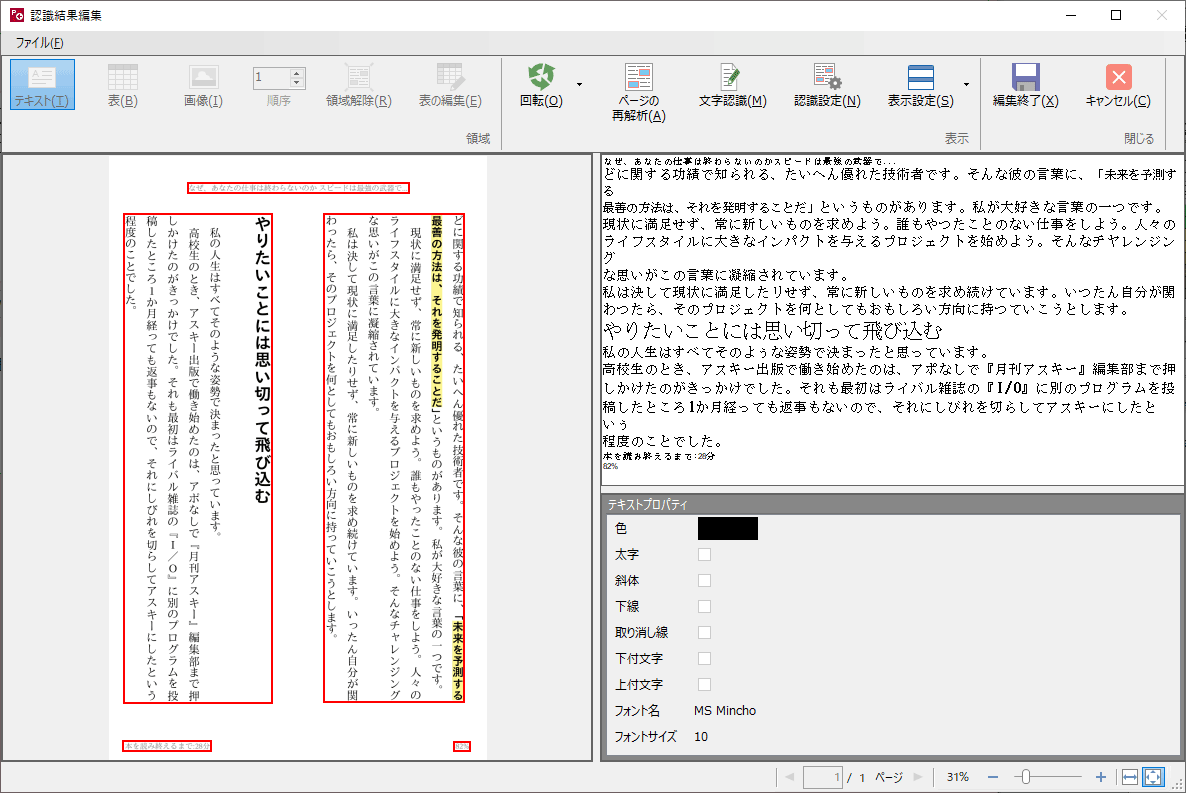
縦書き・横書きの混在も問題ありませんでした。
特に、2段組レイアウトでもちゃんと正しい順序で認識していることにちょっと驚きました(2枚目の画像)。罫線もないのに。
テキスト認識は、フォントによってはカタカナの「ロ」が四角記号になったり、小さい「っ」や「ャ」が大きな「つ」や「ヤ」だと誤認されている箇所はありましたが、まあその辺はOCRならありがちなので仕方ないでしょうね。
任意の画像を読み込んで、OCR機能でテキストを抽出していろんなファイル形式に変換できるのに、「JUST PDF4 データ変換」という名称はやっぱりちょっと損をしているのではないかという気がしてなりません。^^;
とはいえ、たぶん「PDFをOCRでテキストデータにしたい」という需要の方が圧倒的に多いから、そういう名称にしているのでしょうかね。
個人的には「JUST OCRデータ変換」とかだったら、「ああ、OCRで文字認識ができてデータ形式を変換できるのだな」と(名称だけから)理解できたと思うのですけども。
まあ、OCRという名称もそこまで一般に広く認識されているわけでもないでしょうからね……。(^_^;)
何にしても、ジャストシステム製の「JUST PDF4 データ変換」が意外と使えたという話でした。
◆JUST PDF 4 【データ変換】 通常版 ダウンロード版(@Amazon.co.jp)
この日記へのコメントはお気軽に! コメント数:0件
(前の記事) « 各ブラウザのキャッシュデータ保存フォルダを移動するためにシンボリックリンクを作る方法
前後のエントリ
< 旧 / 新 >
(次の記事) 逆流性食道炎かと思ったら胃食道逆流症だった話 »
コメント数: 0件